![]()
Predictive Analytics Software
Document workplace safety risks and incidents in seconds to help maintain a 100% safe and compliant environment for all employees.
- Mobile Data Collection for Safety Inspections and Observations
- Analyze the data to uncover actionable information
- Communicate the results in real time
[http-referer]

Advanced and Predictive Analytics can Improve Your Company's Safety Culture
Training, post-incident analysis, safety consulting services, and other efforts only produce short-term results and are often implemented after incident costs are already incurred. These safety program costs crop up again and again as routines become outdated and start posing risks.
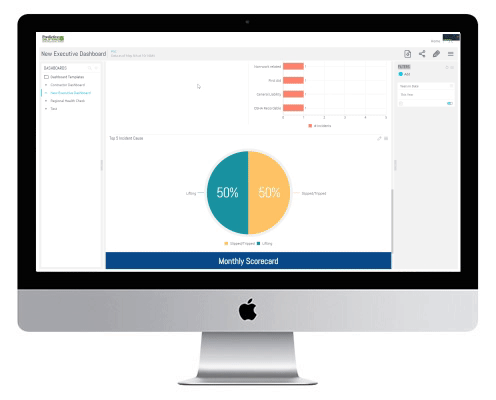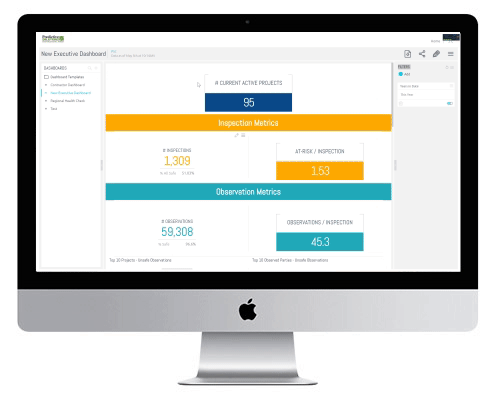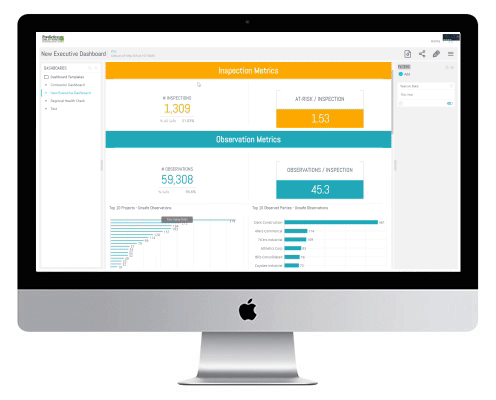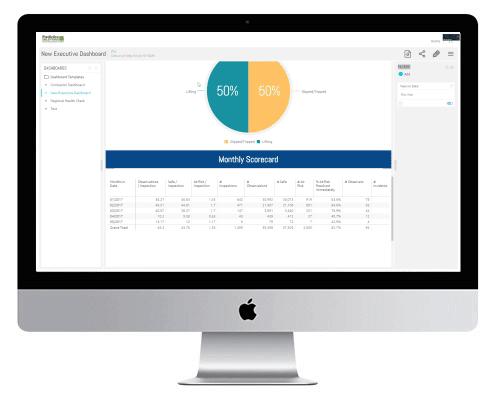
Collect high-quality safety data using mobile phones and tablets.
Analyze the data to uncover actionable information and even leading indicators and predictions about future risk.
Communicate the results in real time to those who are at risk and to those who can take action to prevent incidents and injuries.
What is SafetyNet?
SafetyNet employs advanced and predictive analytics to keep you ahead of disaster. By recording data from inspections and on-site observations, SafetyNet creates a matrix of leading indicators and predictions on future risk in real time.
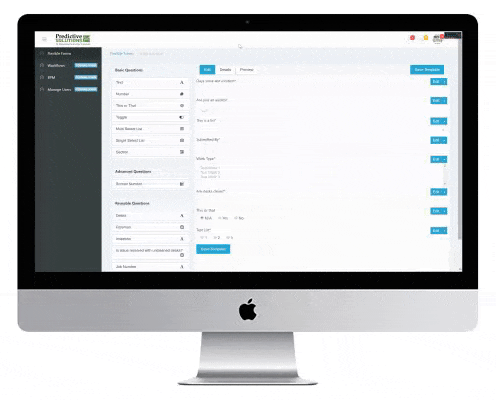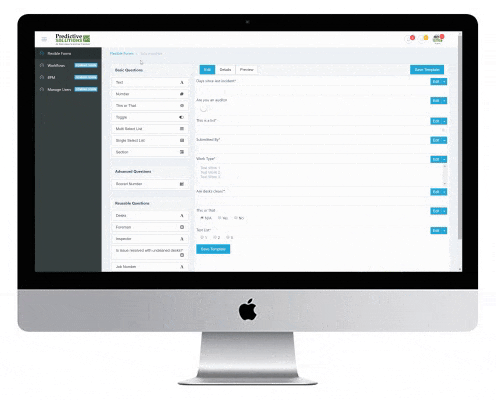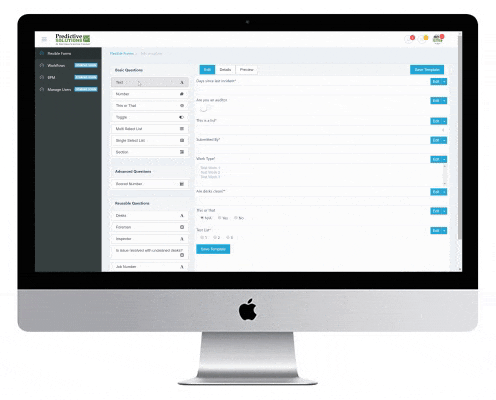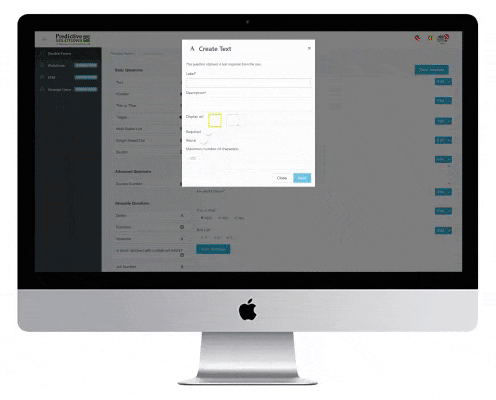
Predictive Analytics Software makes it easy to collect, analyze, and communicate critical data
Many companies struggle to efficiently collect the right data from the field to improve their safety outcomes.
Is your data collection process plagued by pencil-whipping? Are your inspectors and observers just “going through the motions” resulting in a “garbage in, garbage out” program? Reliable predictions are the result of reliable data.
Many companies are drowning in data, but can’t make any sense of it. SafetyNet helps companies turn their raw data into actionable information. SafetyNet employs advanced and predictive analytics tools to help companies trend, forecast, predict, and derive leading indicators from their data.
In order to drive better safety outcomes, immediate hazards need to be communicated to frontline workers in the field or on the job. SafetyNet can notify employees at all levels of the organization instantly when high hazard issues arise and need their attention. Further, SafetyNet can help identify and track to closure, unsafe or non-conforming issues that can’t be solved immediately. Finally, SafetyNet can provide management reports on current and future risk, how that risk is being managed, and what the outcomes of those efforts are.
Expand your knowledge of connected safety with these featured resources

whitepaper
Learn how to maximize your organization's return on investment (ROI) by choosing the most appropriate software solution for your business...

whitepaper
This whitepaper covers all you need to know about the compliance process, from what’s involved to how you can reduce the stress with cutting-edge technology...

whitepaper
Lean how to utilize the benefits of technology, not just to improve workplace safety, but to actively gain the commitment of workers in your safety program...
